@article{hu2024ADAS,title={Automated Design of Agentic Systems},author={Hu, Shengran and Lu, Cong and Clune, Jeff},journal={International Conference on Learning Representations},year={2025},}
Intelligent Go-Explore: Standing on the Shoulders of Giant Foundation Models
@article{lu2024IntelligentGoExplore,title={{Intelligent Go-Explore}: Standing on the Shoulders of Giant Foundation Models},author={Lu, Cong and Hu, Shengran and Clune, Jeff},journal={International Conference on Learning Representations},year={2025},}
Thought Cloning: Learning to Think while Acting by Imitating Human Thinking
Language is often considered a key aspect of human thinking, providing us with exceptional abilities to generalize, explore, plan, replan, and adapt to new situations. However, Reinforcement Learning (RL) agents are far from human-level performance in any of these abilities. We hypothesize one reason for such cognitive deficiencies is that they lack the benefits of thinking in language and that we can improve AI agents by training them to think like humans do. We introduce a novel Imitation Learning framework, Thought Cloning, where the idea is to not just clone the behaviors of human demonstrators, but also the thoughts humans have as they perform these behaviors. While we expect Thought Cloning to truly shine at scale on internet-sized datasets of humans thinking out loud while acting (e.g. online videos with transcripts), here we conduct experiments in a domain where the thinking and action data are synthetically generated. Results reveal that Thought Cloning learns much faster than Behavioral Cloning and its performance advantage grows the further out of distribution test tasks are, highlighting its ability to better handle novel situations. Thought Cloning also provides important benefits for AI Safety and Interpretability, and makes it easier to debug and improve AI. Because we can observe the agent’s thoughts, we can (1) more easily diagnose why things are going wrong, making it easier to fix the problem, (2) steer the agent by correcting its thinking, or (3) prevent it from doing unsafe things it plans to do. Overall, by training agents how to think as well as behave, Thought Cloning creates safer, more powerful agents.
@article{hu2023ThoughtCloning,title={{Thought Cloning}: Learning to Think while Acting by Imitating Human Thinking},author={Hu, Shengran and Clune, Jeff},journal={Advances in Neural Information Processing Systems},volume={36},year={2023},}
Accelerating Multi-Objective Neural Architecture Search by Random-Weight Evaluation
Shengran Hu, Ran Cheng, Cheng He, Zhichao Lu, and
2 more authors
For the goal of automated design of high-performance deep convolutional neural networks (CNNs), Neural Architecture Search (NAS) methodology is becoming increasingly important for both academia and industries. Due to the costly stochastic gradient descent (SGD) training of CNNs for performance evaluation, most existing NAS methods are computationally expensive for real-world deployments. To address this issue, we first introduce a new performance estimation metric, named Random-Weight Evaluation (RWE) to quantify the quality of CNNs in a cost-efficient manner. Instead of fully training the entire CNN, the RWE only trains its last layer and leaves the remainders with randomly initialized weights, which results in a single network evaluation in seconds. Second, a complexity metric is adopted for multi-objective NAS to balance the model size and performance. Overall, our proposed method obtains a set of efficient models with state-of-the-art performance in two real-world search spaces. Then the results obtained on the CIFAR-10 dataset are transferred to the ImageNet dataset to validate the practicality of the proposed algorithm. Moreover, ablation studies on NAS-Bench-301 datasets reveal the effectiveness of the proposed RWE in estimating the performance compared with existing methods.
@inproceedings{hu2021RWE,author={Hu, Shengran and Cheng, Ran and He, Cheng and Lu, Zhichao and Wang, Jing and Zhang, Miao},title={Accelerating Multi-Objective Neural Architecture Search by Random-Weight Evaluation},booktitle={Complex & Intelligent Systems},year={2021},}
Multi-objective Neural Architecture Search with Almost No Training
Shengran Hu, Ran Cheng, Cheng He, and Zhichao Lu
In Evolutionary Multi-Criterion Optimization , 2021
In the recent past, neural architecture search (NAS) has attracted increasing attention from both academia and industries. Despite the steady stream of impressive empirical results, most existing NAS algorithms are computationally prohibitive to execute due to the costly iterations of stochastic gradient descent (SGD) training. In this work, we propose an effective alternative, dubbed Random-Weight Evaluation (RWE), to rapidly estimate the performance of network architectures. By just training the last linear classification layer, RWE reduces the computational cost of evaluating an architecture from hours to seconds. When integrated within an evolutionary multi-objective algorithm, RWE obtains a set of efficient architectures with state-of-the-art performance on CIFAR-10 with less than two hours’ searching on a single GPU card. Ablation studies on rank-order correlations and transfer learning experiments to ImageNet have further validated the effectiveness of RWE.
@inproceedings{hu2021AlmostNoTraining,author={Hu, Shengran and Cheng, Ran and He, Cheng and Lu, Zhichao},title={Multi-objective Neural Architecture Search with Almost No Training},booktitle={Evolutionary Multi-Criterion Optimization},year={2021},publisher={Springer International Publishing},pages={492--503},}
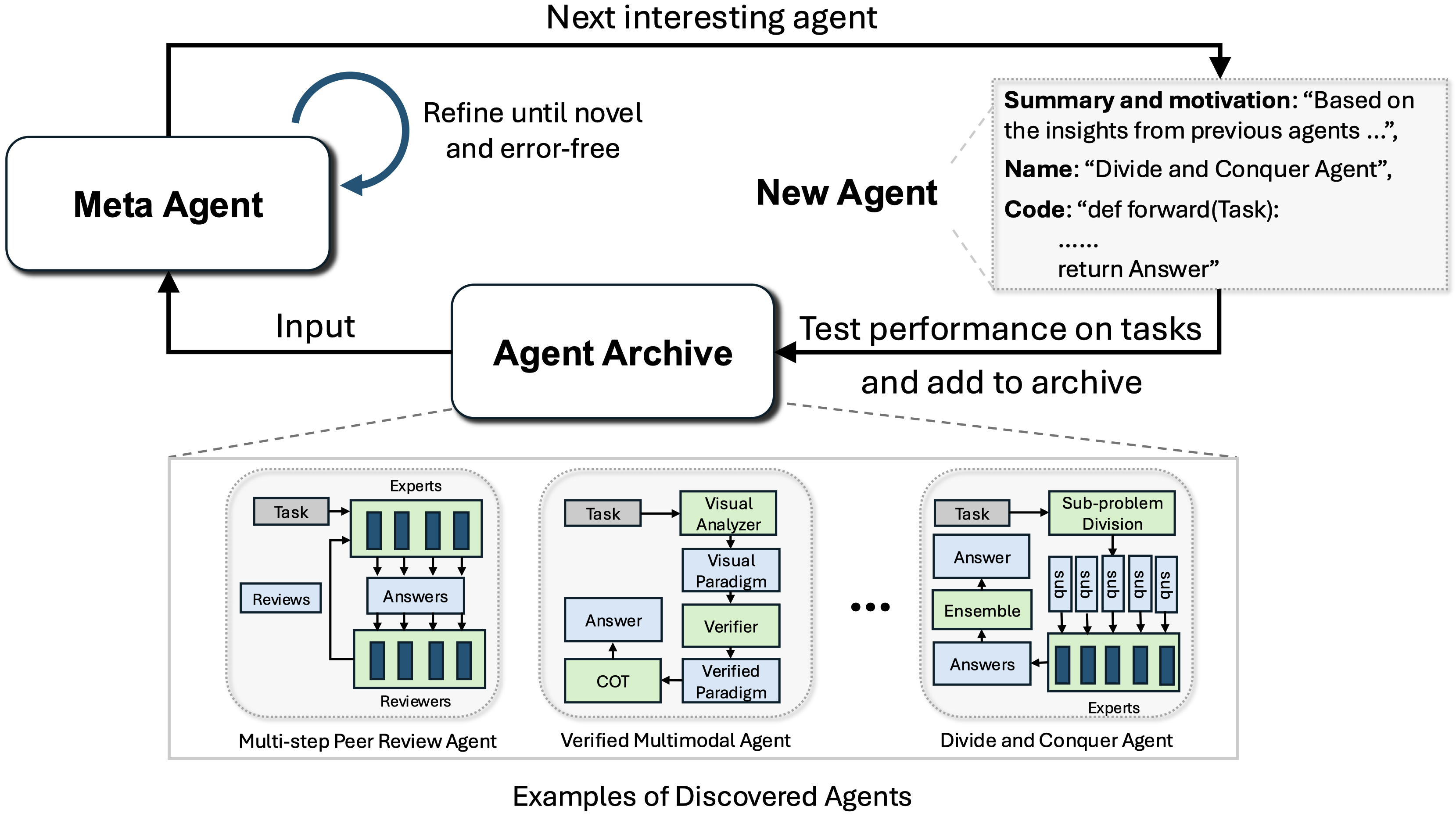 Automated Design of Agentic SystemsInternational Conference on Learning Representations (ICLR), 2025🏆 Outstanding Paper (NeurIPS 2024 Open-World Agent Workshop)
Automated Design of Agentic SystemsInternational Conference on Learning Representations (ICLR), 2025🏆 Outstanding Paper (NeurIPS 2024 Open-World Agent Workshop)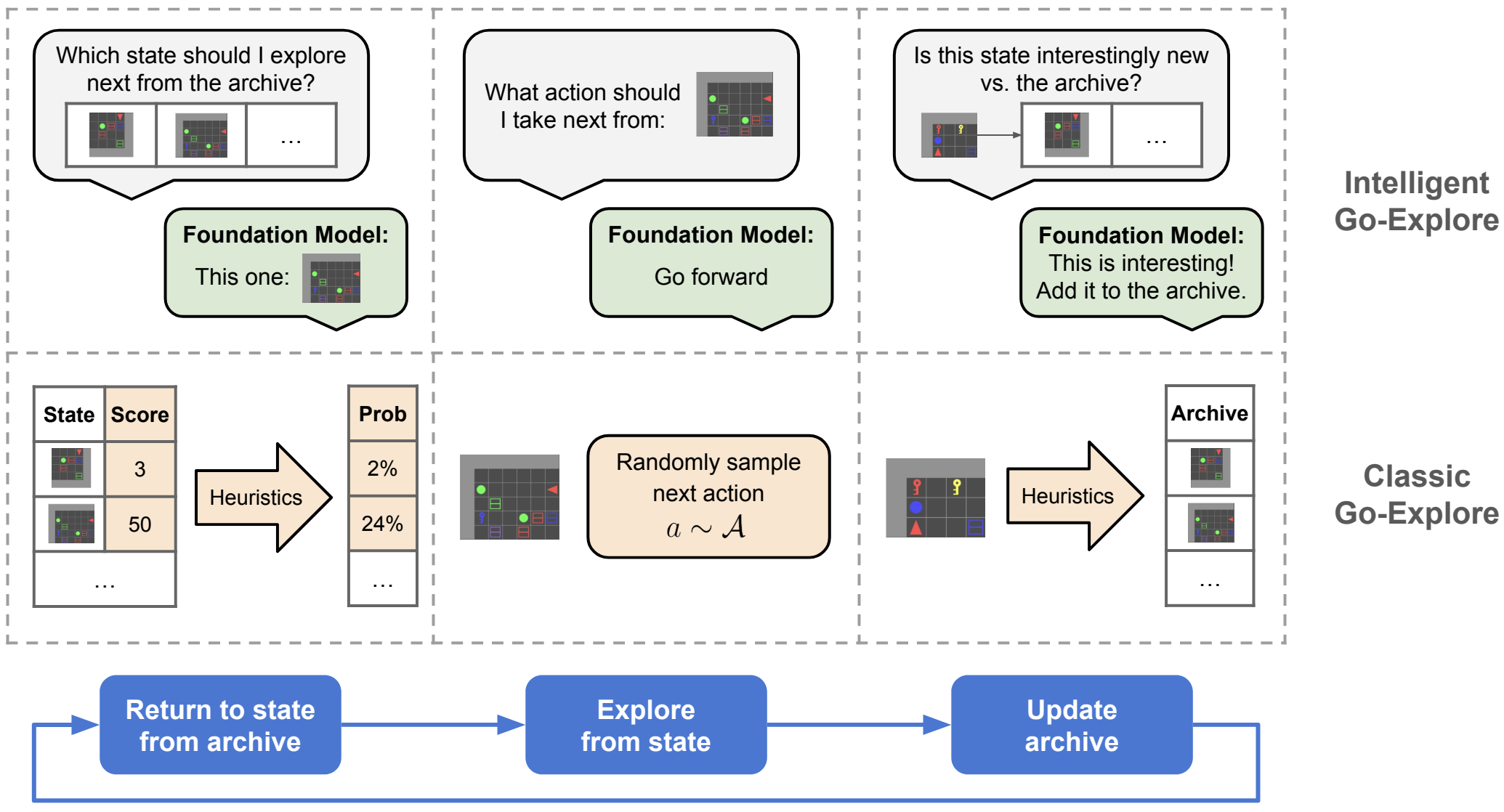 Intelligent Go-Explore: Standing on the Shoulders of Giant Foundation ModelsInternational Conference on Learning Representations (ICLR), 2025
Intelligent Go-Explore: Standing on the Shoulders of Giant Foundation ModelsInternational Conference on Learning Representations (ICLR), 2025

 Thought Cloning: Learning to Think while Acting by Imitating Human ThinkingAdvances in Neural Information Processing Systems (NeurIPS), 2023Spotlight (top 3.1% in 12,343)
Thought Cloning: Learning to Think while Acting by Imitating Human ThinkingAdvances in Neural Information Processing Systems (NeurIPS), 2023Spotlight (top 3.1% in 12,343)

